Cohen's kappa is the statistic that appears in the methods section of nearly every observational CBT study that reports inter-rater reliability. It is the field's default headline number — the single coefficient that signals "the raters agreed enough to be trusted." It also, on its own, leaves enough about rater calibration undescribed that two studies reporting identical kappa values can have very different actual rater behaviour underneath, and the difference matters in ways the standard reporting does not surface.
This is not an argument against kappa. It is an argument that kappa as a single reported statistic is doing less work than the methods sections it appears in tend to imply.
What kappa is
Cohen's 1960 paper introduced the coefficient now bearing his name as a chance-corrected agreement statistic for nominal categories. The idea was simple and good. Two raters classifying the same items will agree some proportion of the time by chance alone; raw agreement percentages do not separate that chance agreement from agreement driven by actual rater skill or instrument quality. Kappa subtracts out the chance-expected agreement and rescales what is left, producing a coefficient that runs from minus one (perfect disagreement) through zero (agreement no better than chance) to one (perfect agreement).
The conventional benchmarks come from Landis and Koch's 1977 paper: above 0.8 "almost perfect," 0.6–0.8 "substantial," 0.4–0.6 "moderate," and so on. These labels have always been more rules-of-thumb than statistical fact — Landis and Koch said so themselves — but they have, over five decades, calcified into the de facto cut-points that reviewers and journals expect. For nominal categories of roughly balanced prevalence, kappa does the job it was designed for.
What kappa is not
Where kappa starts to mislead is the territory CBT research most often operates in: ordinal scales with uneven prevalence, where some categories are common and others are rare, and where the magnitude of disagreement matters rather than just whether there is disagreement.
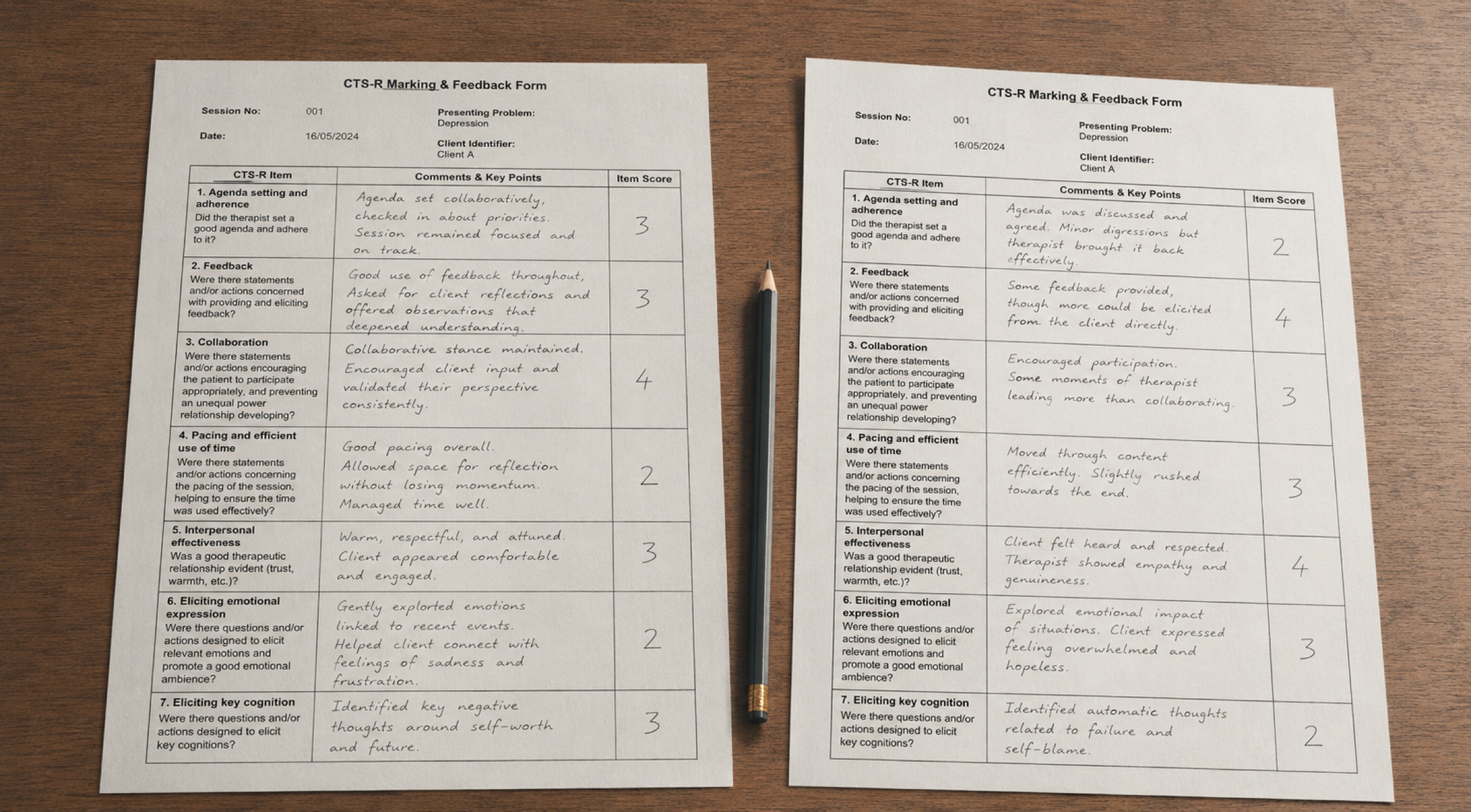
The CTS-R is the obvious example. Its items are scored 0–6 on a definitional scale where 3 is the standard threshold of competence. The empirical distribution of CTS-R scores in research samples clusters heavily around 3–4; the tails are sparse. This distribution interacts with kappa in two well-documented ways.
Prevalence sensitivity — sometimes called the kappa paradox after Feinstein and Cicchetti's 1990 paper — is the phenomenon whereby kappa can be low even when raw agreement is high, provided one category dominates the distribution. The intuition is mathematical: when most ratings fall in one category, the chance-expected agreement is also very high, and subtracting a high chance-expected agreement from a high observed agreement leaves a small numerator over a small denominator. Two raters who agreed 95% of the time on CTS-R items, with most scores clustered around 3–4, can produce kappa values that look mediocre. The statistic is sensitive to the prevalence distribution in a way the raw agreement is not.
Bias sensitivity is the second documented limitation. When two raters have a systematic offset — rater A consistently scoring 0.5 points higher than rater B on the same items — kappa can mask the bias because the disagreements are structured rather than random. A naive kappa calculation does not separate "raters disagreeing randomly" from "raters disagreeing systematically"; both are penalised, but the implications for the underlying data are very different. Two studies can report kappa equals 0.65, with one dataset showing clean random disagreement and the other showing systematic between-rater offset. The kappa coefficient does not distinguish these.
What else needs to be reported alongside kappa
The methodological literature has, for decades, recommended that observational rating studies report a battery of agreement indices rather than kappa alone. The recommendations are not controversial; they are just not consistently followed.
Weighted kappa. Cohen's 1968 paper introduced a weighted version of kappa for ordinal scales where the degree of disagreement matters. On a CTS-R item, a one-point disagreement is not the same as a four-point disagreement, but unweighted kappa treats both as equally bad. Linear or quadratic weighting penalises larger disagreements more than smaller ones. For any ordinal instrument, weighted kappa should be the default rather than the supplement.
Intra-class correlation coefficient. For rating distributions that are effectively continuous — or ordinal enough that the difference between adjacent categories is meaningful and roughly constant — the ICC handles the data more gracefully than kappa. ICC is itself a family of coefficients (Shrout and Fleiss's 1979 paper set out the standard classification), and the choice of variant depends on whether raters are treated as fixed or random effects and whether absolute agreement or consistency is the question.
Raw agreement at exact, within-1, and within-2 levels, broken down by item. This is the part of the recommended battery that costs the least to compute and conveys the most. Item-level breakdowns surface the items on which raters are systematically struggling, separately from the items on which they are well-calibrated.
Bias indices. A reported statistic that captures whether raters have a systematic offset — the kind that bias sensitivity masks in kappa — is worth its modest computational cost. The simplest form is the mean difference between raters across items; more elaborate forms model the offset and its standard error.
Drift of agreement over time across the rater cohort. Agreement at calibration baseline is one thing; agreement six months into the trial, after the cohort has been rating different sessions in different contexts, is another. A rater cohort that started well-calibrated and has been quietly diverging since month one is producing fidelity data of decaying quality, and the only way to see that decay is to recompute the indices at intervals and track them as a time series.
The trial-fidelity application
The trial fidelity infrastructure piece takes up the broader argument that CBT trials need continuous fidelity instrumentation rather than periodic sampled tape rating. The inter-rater reliability question is the methodological undercarriage of that argument.
A trial that reports "inter-rater reliability kappa = 0.72, established at the calibration phase" is reporting a number that may or may not mean what readers assume. It does not tell readers whether weighted kappa would tell the same story, whether one rater was scoring systematically higher than the others, which items showed the worst agreement, whether agreement held up across the months that followed calibration, or whether new raters joining mid-trial went through the same calibration process or were trained more informally. Without the supplementary indices and their time-series form, the headline kappa is a snapshot that can be read more or less optimistically depending on the assumptions the reader brings.
The drift detection in RCTs piece treats the parallel problem on the therapist side. Rater drift is the same phenomenon on the measurement side. If the instrument is drifting at the same time as the thing being measured, the trial is producing data of unknown reliability about a process of unknown fidelity, which is the worst possible epistemic position to be in.
The calibration discipline
Maintaining inter-rater reliability across the life of a multi-year trial requires periodic re-calibration of the rater cohort. Not just initial training. Not just a calibration set scored at the start. Periodic, structured recalibration through the trial, with the agreement indices recomputed each time and the divergence patterns surfaced as actionable signal.
What this looks like in practice is not exotic. A calibration set of sessions is established at the start of the trial. Every six months — or more frequently in trials with high rater turnover — every rater in the active cohort scores a randomly selected subset of the calibration set, and the agreement indices are recomputed. Raters whose agreement with the cohort baseline has slipped are flagged for re-training; items on which the cohort as a whole has drifted are flagged for re-anchoring; new raters joining the cohort score the calibration set in full before being released to live rating.
The labour cost is real but bounded. The labour cost of not doing it is much larger and falls in the wrong place. A trial that discovers, at the end of analysis, that its rater cohort drifted at month nine and produced six months of subtly miscalibrated data has no clean way to recover. There is a connection here to the therapist drift literature: drift in clinicians and drift in raters are the same phenomenon — sustained behaviour under conditions of imperfect feedback gradually moves away from the trained baseline — and the remedies are the same. The fact that the field accepts the argument for therapists but has not consistently applied it to its own raters is one of those quiet asymmetries that, once noticed, is difficult to unsee.
The single-statistic temptation
It is genuinely easier to report one number. Methods sections are short, reviewers are time-pressured, and the field's collective muscle memory has settled on kappa as the inter-rater reliability statistic. The case for replacing it with a battery has to clear the bar that the battery does additional work the single statistic could not do.
The argument here is that the battery does clear that bar. Kappa alone cannot distinguish clean random disagreement from systematic bias; the supplementary indices can. Kappa alone cannot show item-level patterns; raw agreement by item can. Kappa alone is a snapshot; the time-series form can show drift. The implication is straightforward: report kappa if you must, but report it alongside the indices that fill in what kappa does not capture. The reader is owed the fuller picture.
Supervisia Research builds the inter-rater reliability instrumentation into the rater workflow itself.
The rater pathways surface weighted kappa, ICC, raw agreement at exact/within-1/within-2 levels by item, bias indices, and the time-series trajectory of each index across the life of the trial. Re-calibration prompts trigger when the divergence trajectory suggests it, rather than waiting for the end-of-trial analysis. New raters route through a standing calibration set before they are released to live rating. The supplementary indices stop being something the trial team has to assemble ad hoc and become the default reporting.
References
- Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1), 37–46. DOI: 10.1177/001316446002000104.
- Cohen, J. (1968). Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. Psychological Bulletin, 70(4), 213–220.
- Landis, J. R. & Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics, 33(1), 159–174.
- Feinstein, A. R. & Cicchetti, D. V. (1990). High agreement but low kappa: I. The problems of two paradoxes. Journal of Clinical Epidemiology, 43(6), 543–549.
- Shrout, P. E. & Fleiss, J. L. (1979). Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86(2), 420–428.
- Blackburn, I.-M., James, I. A., Milne, D. L., Baker, C., Standart, S., Garland, A. & Reichelt, F. K. (2001). The Revised Cognitive Therapy Scale (CTS-R): Psychometric properties. Behavioural and Cognitive Psychotherapy, 29(4), 431–446.
- Waller, G. & Turner, H. (2016). Therapist drift redux: Why well-meaning clinicians fail to deliver evidence-based therapy, and how to get back on track. Behaviour Research and Therapy, 77, 129–137. DOI: 10.1016/j.brat.2016.01.007. PubMed: 26752326.
Last updated: May 2026